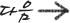기본적으로 Visual studio 2010을 기준으로 설명하되, 소스코드는 gcc에서도 문제없이 작동한다.
SSE2를 사용하기 위해서는 [Project properties]에서 C/C++의 Code Generation 부분에서
Enable Enhanced Instruction Set을 /SSE2로 세팅한다.
그리고 다음 헤더 파일을 추가한다.
#include <xmmintrin.h>
행렬의 구조체는
typedef struct _Matrix
{
int row, col;
float **matrix;
} Matrix;
와 같이 만든다. row와 col은 각각 행과 열의 크기(길이)를 뜻한다.
SSE2를 사용할 때는 기본적으로 float 4개를 한번에 연산하는 것을 목표로 한다.
(double같은경우 2개를 한번에 연산)
행렬의 실제 값이 들어갈 2차원 배열은, malloc()가 아닌 _aligned_malloc()를 이용해야 한다.
2차원 배열을 동적으로 만들때, 열 배열을 가리킬 행 배열은 malloc()로 할당해도 상관없지만,
열 배열은 반드시 _aligned_malloc()로 할당해야 하는데, 이유는 최소한 4개의 float공간이
물리적으로 연속적으로 할당받음이 보장되어야 하기 때문이다.
malloc()로 연속적으로 할당해도, 가상메모리상에서만 연속일뿐, 실제로는 연속적이지 않다.
_aligned_malloc()에서 첫번째 인자는, malloc()에서의 첫번째 인자와 같은 의미로 사용하면 된다.
할당받을 배열의 길이를 첫번째 인자로 넣어준다.
그리고 _aligned_malloc()의 두번째 인자는, aligned되어야 할 크기를 넣어줘야 한다.
즉, 반드시 연속적으로 할당해야할 크기를 말한다.
float 4개를 연속해서 받아야 하기 때문에, sizeof(float) * 4를 두번째 인자로 넣어준다. (즉, 16)
float **make2dArray(int rows, int cols)
{
float **x = NULL;
int height = cols, width = rows;
x = (float **)malloc(height*sizeof(float*));
for(int i=0; i<height; i++){
x[i] = (float *)_aligned_malloc(((width*sizeof(float)+15)>>4)<<4, 16);
}
return x;
}
해제 역시 _aligned_free()로 해제한다.
void delete2dArray(float **arr, int rows, int cols)
{
if( arr != NULL ){
for(int i=0; i<cols; i++){
_aligned_free(arr[i]);
}
free(arr);
}
arr = NULL;
}
다음과 같은 함수가 있으면 테스트하기 편하다.
void initRandom(Matrix& m)
{
for(int i=0; i<m.col; i++){
for(int j=0; j<m.row; j++){
m.matrix[i][j] = (float)(rand()%4);
}
}
}
void initZero(Matrix& m)
{
for(int i=0; i<m.col; i++){
for(int j=0; j<m.row; j++){
m.matrix[i][j] = (float)(0.0f);
}
}
}
bool makeMatrix(Matrix& m, int col, int row)
{
m.matrix = make2dArray(row, col);
m.col = col;
m.row = row;
return true;
}
bool deleteMatrix(Matrix& m)
{
delete2dArray(m.matrix, m.row, m.col);
m.col = 0;
m.row = 0;
return true;
}
SSE2를 사용하지 않고, 두 행렬 m1, m2를 곱하려면 다음과 같이 구현하면 된다.
bool Multiply(Matrix& m1, Matrix& m2, Matrix& res)
{
bool bRet = false;
do
{
if( m1.row != m2.col ) break;
if( m1.col != res.col ) break;
if( m2.row != res.row ) break;
for(int i=0; i<m1.col; i++){
for(int j=0; j<m2.row; j++){
float e = 0.0f;
for(int k=0; k<m1.row; k++){
e += m1.matrix[i][k] * m2.matrix[k][j];
}
res.matrix[i][j] = e;
}
}
bRet = true;
} while(0);
return bRet;
}
SSE2를 이용한 행렬 곱 함수이다.
bool MultiplySSE(Matrix& m1, Matrix& m2, Matrix& res)
{
if( m1.row != m2.col ) break;
if( m1.col != res.col ) break;
if( m2.row != res.row ) break;
initZero(res);
for(int i=0; i<m1.col; i++) {
for(int j=0; j<m1.row; j++) {
int k = 0;
int n = (m2.row - (m2.row % 4))/4;
__m128 sse_m1 = _mm_set1_ps(m1.matrix[i][j]);
while( n --> 0 ){
__m128 *sse_mR = (__m128 *)(res.matrix[i]+k);
__m128 *sse_m2 = (__m128 *)(m2.matrix[j]+k);
*sse_mR = _mm_add_ps(*sse_mR, _mm_mul_ps(sse_m1, *sse_m2));
k += 4;
}
switch( m2.row - k ) {
case 3: res.matrix[i][k] += m1.matrix[i][j] * m2.matrix[j][k]; k++;
case 2: res.matrix[i][k] += m1.matrix[i][j] * m2.matrix[j][k]; k++;
case 1: res.matrix[i][k] += m1.matrix[i][j] * m2.matrix[j][k]; k++;
}
}
}
}
4의 배수만큼은 sse로 계산하고, 나머지 부분은 그냥 평범하게 계산하였다.
여기서 순서가 중요하다.
열의 크기가 23인 행렬을 계산할 경우, 4개의 float를 한번에 5번 sse로 계산한뒤, 나머지 3개를 계산하면 문제없다. 하지만, 먼저 3개를 계산하고나서, 5번의 sse연산을 할 경우 문제가 된다.
이유는 열 벡터를 0번째부터 aligned되게 할당하였기 때문이다.
즉, _aligned_malloc( 23, 4*sizeof(float) )으로 할당한 경우, 메모리는
[3][4][4][4][4][4] 가 아니라
[4][4][4][4][4][3] 처럼 배치된다.
따라서 remain 3은 맨 마지막에 고려해야 한다.
main()에서는 다음과 같이 테스트하였다.
int main(int argc, char *argv[]){
,,, 생략 ,,,
makeMatrix(m1, i, j);
makeMatrix(m2, j, k);
makeMatrix(res1, m1.col, m2.row);
makeMatrix(res2, m1.col, m2.row);
initRandom(m1);
initRandom(m2);
Multiply(m1, m2, res1);
MultiplySSE(m1, m2, res2);
,,, 생략 ,,,
}
'c/c++' 카테고리의 다른 글
| STL std::set에서 find, insert시 동등성 비교 (0) | 2012.11.26 |
|---|---|
| 크기 0짜리 배열 (0) | 2012.10.04 |
| 행렬 곱 row만으로 연산하기 (0) | 2012.09.11 |
| c++ vector 등 연속 메모리 컨테이너를 배열처럼 쓰는 방법 (0) | 2012.09.09 |
| multimap에서 equal_range()로 아무것도 못찾은 경우 (0) | 2012.09.01 |